Pythonで重複ファイルを自動検出&整理する方法|画像・PDF対応のGUIツール付き解説
PCのフォルダに、同じファイルがいくつもあって困った経験はありませんか?
特に画像やPDFを頻繁に扱う方は、「ファイル名は違うけど中身は同じ」というケースが多く、気づかないうちに容量を圧迫していることもあります。
この記事では、筆者が実務で使用しているPython製の重複ファイル検出ツールを紹介します。
完全一致の重複ファイルを自動で検出し、「duplicates」フォルダに移動。さらに、GUI操作で初心者でも簡単に使えるようにしています。
Pythonを使えば、ファイル整理もここまで“自動化”できるようになります。
このツールの目的と機能
- フォルダ内の完全一致ファイル(PDF・画像含む)を検出
- 重複ファイルを自動で「duplicates」フォルダに移動
- 処理結果を「duplicate_log.txt」に記録
- GUIで操作できるのでコマンド不要
【実務での効果】
筆者の環境では、10GB超の画像フォルダをスキャンした際、約800個の重複ファイルを自動で整理できました。
特にプロジェクト資料や撮影データなど、同名・異名ファイルが混在する環境に最適です。
重複ファイルを検出する仕組み:ハッシュ値(MD5)とは?
ファイルの中身を一つひとつ比較するのは非効率です。
そこで使うのがハッシュ値(MD5)です。
ハッシュ値とは「ファイルの内容から生成される一意の文字列」で、内容が同じであればファイル名が違っても同じハッシュ値になります。
import hashlib
def get_file_hash(filepath):
hasher = hashlib.md5()
with open(filepath, 'rb') as f:
for chunk in iter(lambda: f.read(4096), b""):
hasher.update(chunk)
return hasher.hexdigest()
この関数で生成したハッシュ値を比較すれば、ファイルの内容が完全に一致しているかどうかを高速・正確に判定できます。
GUI付きのPythonスクリプト(実行用コード)
以下が完成版スクリプトです。
PythonとTkinterが動作する環境なら、コピーしてすぐに実行できます。
import os
import hashlib
import shutil
import tkinter as tk
from tkinter import filedialog, messagebox
from datetime import datetime
def get_file_hash(filepath):
hasher = hashlib.md5()
try:
with open(filepath, 'rb') as f:
for chunk in iter(lambda: f.read(4096), b""):
hasher.update(chunk)
return hasher.hexdigest()
except Exception as e:
return None
def find_unique_files_and_move_duplicates(directory, log_file_path):
seen_hashes = set()
unique_files = []
skipped_files = []
duplicates_dir = os.path.join(directory, "duplicates")
os.makedirs(duplicates_dir, exist_ok=True)
with open(log_file_path, 'w', encoding='utf-8') as log_file:
log_file.write(f"Duplicate File Detection Log - {datetime.now()}\n")
log_file.write(f"Target Directory: {directory}\n\n")
for root, _, files in os.walk(directory):
if root.startswith(duplicates_dir):
continue
for filename in files:
filepath = os.path.join(root, filename)
file_hash = get_file_hash(filepath)
if file_hash is None:
log_file.write(f"Error reading file: {filepath}\n")
continue
if file_hash not in seen_hashes:
seen_hashes.add(file_hash)
unique_files.append(filepath)
log_file.write(f"Unique: {filepath}\n")
else:
skipped_files.append(filepath)
try:
dest_path = os.path.join(duplicates_dir, os.path.relpath(filepath, directory))
os.makedirs(os.path.dirname(dest_path), exist_ok=True)
shutil.move(filepath, dest_path)
log_file.write(f"Moved Duplicate: {filepath} -> {dest_path}\n")
except Exception as e:
log_file.write(f"Error moving file: {filepath} - {e}\n")
log_file.write(f"\nTotal Unique Files: {len(unique_files)}\n")
log_file.write(f"Total Moved Duplicate Files: {len(skipped_files)}\n")
return unique_files, skipped_files
def select_directory():
directory = filedialog.askdirectory()
if not directory:
return
log_file_path = os.path.join(directory, "duplicate_log.txt")
unique_files, skipped_files = find_unique_files_and_move_duplicates(directory, log_file_path)
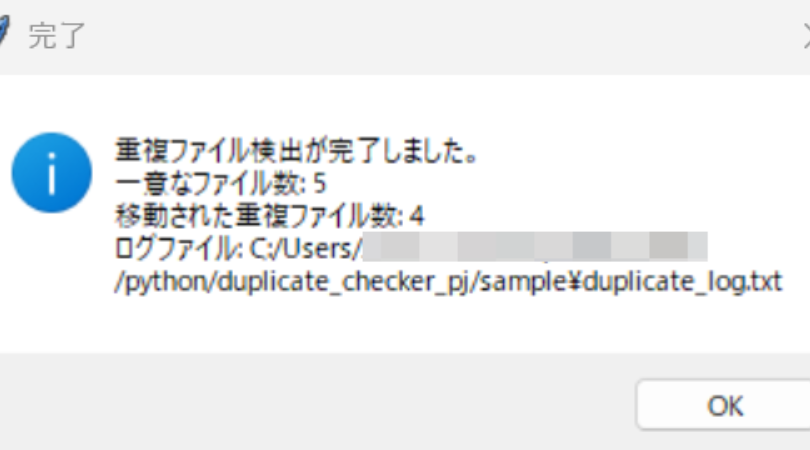
messagebox.showinfo("完了", f"重複ファイル検出が完了しました。\n"
f"一意なファイル数: {len(unique_files)}\n"
f"移動された重複ファイル数: {len(skipped_files)}\n"
f"ログファイル: {log_file_path}")
# GUI構築
root = tk.Tk()
root.title("完全一致ファイル検出ツール")
frame = tk.Frame(root, padx=20, pady=20)
frame.pack()
label = tk.Label(frame, text="フォルダを選択して重複ファイルを検出・整理します。")
label.pack(pady=10)
select_button = tk.Button(frame, text="フォルダを選択", command=select_directory, bg="#d0f0c0")
select_button.pack(pady=10)
root.mainloop()
使い方と実行結果
- 「フォルダを選択」ボタンをクリック
- 対象フォルダを選ぶと、自動で重複ファイルを検出
- 重複ファイルは
duplicatesフォルダに自動移動 - 結果は
duplicate_log.txtに詳細を出力
実際のGUI画面
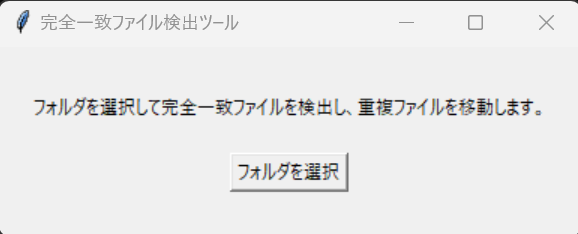
フォルダを選択すると、自動で解析が始まり、完了後に結果がポップアップ表示されます。
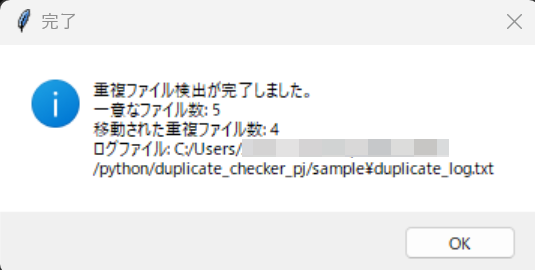
実行例:整理前と整理後
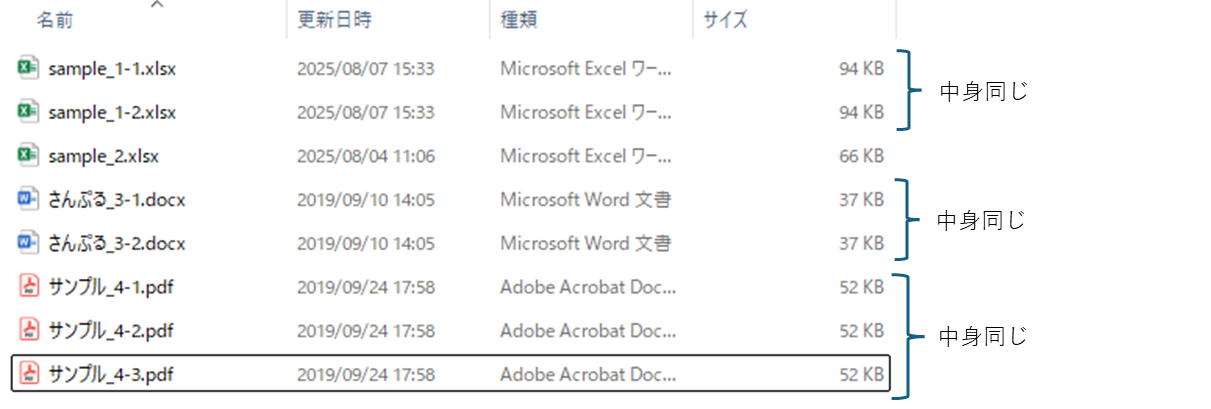

重複ファイルは自動的に「duplicates」フォルダに移動し、オリジナルだけが残ります。
ログファイル(duplicate_log.txt)で処理履歴も確認できます。
ログファイルの内容例
Duplicate File Detection Log – 2025-09-11 14:00:00
Target Directory: /Users/username/Documents/photosUnique: /Users/username/Documents/photos/img1.jpg
Moved Duplicate: /Users/username/Documents/photos/copy_img1.jpg → /Users/username/Documents/photos/duplicates/copy_img1.jpgTotal Unique Files: 1
Total Moved Duplicate Files: 1
痒いところに手が届く!カスタマイズ案
他の重複検出ツールにはない、実務で便利な拡張アイデアを紹介します👇
- 📂 ファイル形式フィルタ(例:画像だけ、PDFだけ)
- 🧠 類似画像の検出(ImageHash や OpenCV を活用)
- 📊 CSV形式でログ出力(Excelで管理しやすい)
- ⚙️ EXE化して社内配布(PyInstaller解説記事 参照)
まとめ
Pythonを使えば、重複ファイル検出のような一見専門的な処理も、数十行のコードでGUIアプリとして作成できます。
今回のツールは、業務用フォルダや写真整理など、さまざまなシーンで役立つ実用的なスクリプトです。
ぜひあなたの環境でも試してみてください。
カスタマイズすれば、画像比較やAIによる類似判定など、より高度な自動整理ツールにも発展できます。