PythonでExcel・Wordを日本語対応PDFに変換する方法|文字化け対策と実用性検証

業務で扱うExcelやWordファイルをPDF化したい場面は多くあります。Pythonを使えば自動化も可能ですが、日本語の文字化けやレイアウト崩れなど、意外とハードルが高いのが現実です。
この記事では、実際に試した3つの方法とその結果、さらに現時点での最適解についてまとめます。
方法1:PyMuPDFでPDF化(テキスト抽出)
最初に試したのは、Pythonの人気PDFライブラリ「PyMuPDF(fitz)」を使って、WordやExcelの内容をテキストとしてPDFに出力する方法です。
コード:page.insert_textbox(rect, “”こんにちは世界””, fontsize=12)
しかし、PyMuPDFのデフォルトフォントは日本語に対応しておらず、「???」などの文字化けが発生。日本語文書には不向きでした。
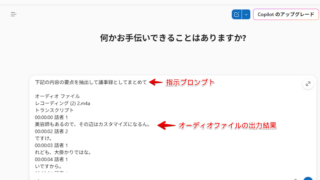
 出力されたPDF
出力されたPDF方法2:PyMuPDFでフォント指定してPDF化
次に、PyMuPDFで日本語フォント(MSゴシックなど)を明示的に指定してみました。
コード:page.insert_textbox(rect, “”こんにちは世界””, fontsize=12, fontfile=””msgothic.ttf””)
しかし、フォントファイルの指定がうまくいかず、need font file or buffer や cannot open resource などのエラーが発生。.ttfではなく.ttc形式のMSゴシックを使うには、フォントインデックスの指定が必要でした。
方法3:Excel・Wordを画像化してPDF化
最終的にたどり着いたのが、ExcelやWordの内容を画像として描画し、それをPDFに変換する方法です。
この方法では、文字化けは解消され、MSゴシック(.ttc)を指定することで日本語も正しく表示されました。
ただし、文字の被りや罫線の表示など、改善すべき点は残っています。
成功:文字化けは解消
- Pillowで画像化
- MSゴシック(.ttc)を ImageFont.truetype() で読み込み
- PyMuPDFで画像をPDFに挿入
コード:font = ImageFont.truetype(“”C:/Windows/Fonts/msgothic.ttc””, 20, index=0)
出力されたPDF。文字が被ってますし罫線が四角形で表示されています。今の力ではここまでが限界でした。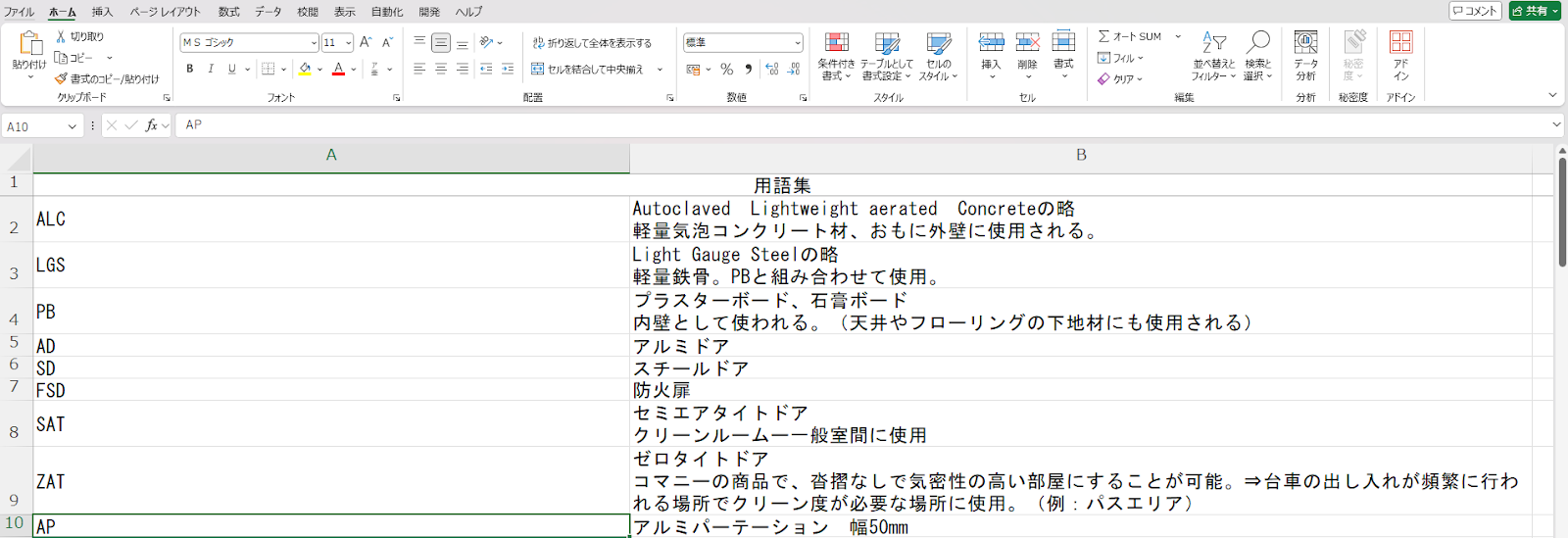 元となったExcelファイル
元となったExcelファイル最終的に使用したPythonコード
以下が、画像化してPDF化するGUIアプリの完全なPythonコードです(MSゴシック.ttc対応)
import os
import io
from tkinter import Tk, Label, Button, filedialog, messagebox
from PIL import Image, ImageDraw, ImageFont
from docx import Document
from openpyxl import load_workbook
import fitz # PyMuPDF
# MSゴシックフォント(.ttc形式)を指定
FONT_PATH = ""C:/Windows/Fonts/msgothic.ttc""
FONT_INDEX = 0 # MSゴシックは通常 index=0 でOK
def word_to_image_pdf(docx_path):
try:
doc = Document(docx_path)
pdf_path = os.path.splitext(docx_path)[0] + ""_image.pdf""
pdf = fitz.open()
for para in doc.paragraphs:
img = Image.new(""RGB"", (800, 600), ""white"")
draw = ImageDraw.Draw(img)
font = ImageFont.truetype(FONT_PATH, 20, index=FONT_INDEX)
draw.text((50, 50), para.text, font=font, fill=""black"")
img_bytes = io.BytesIO()
img.save(img_bytes, format=""PNG"")
img_bytes.seek(0)
page = pdf.new_page(width=800, height=600)
page.insert_image(fitz.Rect(0, 0, 800, 600), stream=img_bytes.read())
pdf.save(pdf_path)
pdf.close()
return f""Word: {os.path.basename(docx_path)} → PDF変換成功""
except Exception as e:
return f""Word: {os.path.basename(docx_path)} → エラー: {e}""
def excel_to_image_pdf(xlsx_path):
try:
wb = load_workbook(xlsx_path)
pdf_path = os.path.splitext(xlsx_path)[0] + ""_image.pdf""
pdf = fitz.open()
for sheet in wb.sheetnames:
ws = wb[sheet]
img = Image.new(""RGB"", (800, 600), ""white"")
draw = ImageDraw.Draw(img)
font = ImageFont.truetype(FONT_PATH, 16, index=FONT_INDEX)
y = 50
for row in ws.iter_rows(values_only=True):
text = "" "".join([str(cell) if cell else """" for cell in row])
draw.text((50, y), text, font=font, fill=""black"")
y += 30
if y > 550:
img_bytes = io.BytesIO()
img.save(img_bytes, format=""PNG"")
img_bytes.seek(0)
page = pdf.new_page(width=800, height=600)
page.insert_image(fitz.Rect(0, 0, 800, 600), stream=img_bytes.read())
img = Image.new(""RGB"", (800, 600), ""white"")
draw = ImageDraw.Draw(img)
y = 50
img_bytes = io.BytesIO()
img.save(img_bytes, format=""PNG"")
img_bytes.seek(0)
page = pdf.new_page(width=800, height=600)
page.insert_image(fitz.Rect(0, 0, 800, 600), stream=img_bytes.read())
pdf.save(pdf_path)
pdf.close()
return f""Excel: {os.path.basename(xlsx_path)} → PDF変換成功""
except Exception as e:
return f""Excel: {os.path.basename(xlsx_path)} → エラー: {e}""
def select_word_files():
filepaths = filedialog.askopenfilenames(filetypes=[(""Word files"", ""*.docx"")])
if filepaths:
results = [word_to_image_pdf(path) for path in filepaths]
messagebox.showinfo(""Word変換結果"", ""\n"".join(results))
def select_excel_files():
filepaths = filedialog.askopenfilenames(filetypes=[(""Excel files"", ""*.xlsx"")])
if filepaths:
results = [excel_to_image_pdf(path) for path in filepaths]
messagebox.showinfo(""Excel変換結果"", ""\n"".join(results))
# GUI構築
root = Tk()
root.title(""Word/Excel 画像PDF変換ツール(MSゴシック .ttc対応)"")
root.geometry(""400x220"")
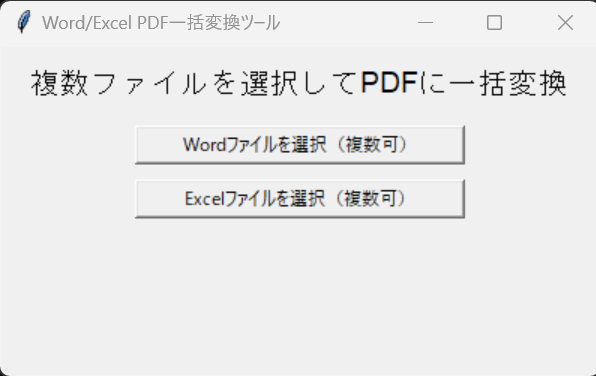
Label(root, text=""ファイルを画像としてPDFに変換"", font=(""Arial"", 14)).pack(pady=10)
Button(root, text=""Wordファイルを選択(複数可)"", command=select_word_files, width=30).pack(pady=5)
Button(root, text=""Excelファイルを選択(複数可)"", command=select_excel_files, width=30).pack(pady=5)
root.mainloop()
GUI
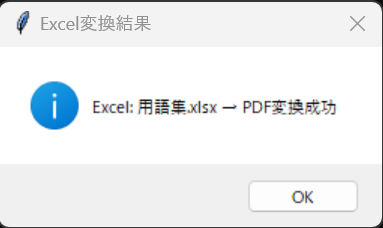 変換に成功するとこんな表示が出ます
変換に成功するとこんな表示が出ます- シンプル設計(ラベル1つ+ボタン2つで迷わない)
- WordとExcelを分けて処理(拡張子に応じた動作)
- 複数ファイル対応(まとめて変換可能)
- 結果を分かりやすく通知(メッセージボックスで一覧表示)
- フォント指定済み(MSゴシック)で文字化け防止
⚠️ 課題点
- 文字の被り:行数が多いと画像サイズを超えてしまい、文字が重なる
- 罫線の表示:Excelの罫線が「□」などで表示されることがある
- フォント依存:フォント指定しないと文字化けするため、環境依存性が高い
- 実用性:レイアウト再現性や編集性に乏しく、業務利用にはまだ課題あり
🔧今後の改善ポイント
- 画像サイズの自動調整(ページ分割やスクロール対応)
- 罫線や表の描画強化(Excelの構造を再現)
- フォント選択機能の追加(GUIで選べるように)
- OCRとの連携(画像PDFからテキスト抽出)
まとめ
PythonでExcel・WordをPDF化するには、日本語対応とレイアウト保持が大きな壁になります。現時点では「画像化してPDF化」が最も安定した方法ですが、実用化にはさらなる工夫が必要です。
今後は、より高品質なPDF出力を目指して、LibreOffice連携やHTMLベースのPDF生成なども検討していきたいと思います。