PDFが圧縮できない理由とは?図面PDFと通常PDFの違いを徹底解説【Pythonスクリプト付き】
記事内に商品プロモーションを含む場合があります
業務で扱うPDFファイルは、報告書・図面・契約書など多岐にわたり、ファイルサイズが大きくなりがちです。
「Pythonで一括圧縮して業務効率化したい!」と思ってスクリプトを組んでみたものの、一部のPDFが圧縮できないという問題に直面することがあります。私なんですが・・・
この記事では、圧縮できるPDFとできないPDFの違いを中心に、実際のエラー例や対処法、Pythonスクリプトも交えて解説します。
Contents
✅ 圧縮できるPDFの特徴
| 圧縮できるPDF | 説明 |
|---|---|
| 画像ベースのPDF | スキャンや写真を含むPDF。画像の解像度を下げることでサイズ削減可能。 |
| テキストベースのPDF | テキスト主体のPDF。再保存や最適化で軽量化できることも。 |
| 構造がシンプルなPDF | ページ数が少なく、リンクや注釈が少ないPDF。 |
❌ 圧縮できないPDFの特徴とエラー例
AutoCADで作成された図面PDF(例:sample_3.pdf)を圧縮しようとしたところ、以下のようなエラーが発生しました。
Error compressing sample_3.pdf: source or target not a PDF
このエラーの原因は以下の通りです。
- ベクター形式(線や図形)で構成されている
PyMuPDFは画像化して圧縮するため、ベクター形式には不向き。 - AutoCAD特有のメタデータが多い
AutoCAD SHX Textなどの特殊なオブジェクトが処理を妨げる。 - 構造が複雑すぎる
ページ数が多く、注釈や図面が密集していると、ライブラリが「PDFとして認識できない」と判断することがある。
🛠 圧縮できないPDFへの対応策とおすすめツール
Pythonスクリプトでは圧縮できないPDF(特にAutoCAD図面など)に対しては、以下のような方法で対応できます。
1. Adobe Acrobatで標準PDFに変換
- 「ファイル」→「別名で保存」→「PDFとして保存」
- ベクター形式を維持しつつ、構造を簡素化できる
2. Ghostscript(無料・オフライン・高機能)
ベクター形式にも対応したコマンドラインツール。画質を調整しながら圧縮可能。
gswin64c -sDEVICE=pdfwrite -dCompatibilityLevel=1.4 -dPDFSETTINGS=/screen \ -dNOPAUSE -dBATCH -dQUIET -sOutputFile=""output.pdf"" ""input.pdf""
コマンド解説
- gswin64c
Windows版 Ghostscript のコマンドライン実行ファイル(64bit, コンソール版)。 - -sDEVICE=pdfwrite
出力デバイスを PDF に指定(つまり PDF を新しく作り直す)。 - -dCompatibilityLevel=1.4
出力する PDF のバージョンを 1.4 に固定(古いビューアでも開けるようにする)。 - -dPDFSETTINGS=/screen
圧縮設定のプリセット。/screen は低解像度表示用に最適化され、ファイルサイズを小さくする代わりに画質が落ちる。
(例:画像は72dpi程度にダウンサンプリング、JPEG圧縮率高め) - -dNOPAUSE -dBATCH -dQUIET
自動処理用のオプション。
・-dNOPAUSE→ ページごとに「続行しますか?」を聞かれない
・-dBATCH→ 処理終了後に自動で終了
・-dQUIET→ ログ出力を最小化 - -sOutputFile=”output.pdf”
出力する PDF ファイルの名前。 - “input.pdf”
入力する PDF ファイル。
3. PDFelement(GUIで簡単操作)

- 高・中・低の圧縮品質を選択可能
- 業務用の図面PDFや契約書におすすめ
4. PDF24 Tools(オンライン・無料)
- ブラウザ上で手軽に圧縮
- 複数ファイルの一括処理も可能
- 機密性の高いPDFはアップロードに注意
🔍 どのツールを使えばいい?
| ツール名 | 特徴 | おすすめ用途 |
|---|---|---|
| Ghostscript | 高機能・オフライン・無料 | 技術者向け、図面PDF |
| PDFelement | GUI・簡単操作・有料版あり | 業務用、画質重視 |
| PDF24 Tools | オンライン・無料・手軽 | 一般用途、非機密PDF |
🐍 PythonでPDFを一括圧縮するGUIスクリプト
以下は、画像ベースのPDFを対象に、一括圧縮できるPythonスクリプト(Tkinter GUI付き)です。
import fitz # PyMuPDF
import os
import tkinter as tk
from tkinter import filedialog, messagebox
from tkinter import ttk
def is_valid_pdf(file_path):
try:
doc = fitz.open(file_path)
doc.close()
return True
except:
return False
def compress_pdf(input_path, output_path, zoom=0.5):
try:
doc = fitz.open(input_path)
new_doc = fitz.open()
for page in doc:
pix = page.get_pixmap(matrix=fitz.Matrix(zoom, zoom))
img_pdf = fitz.open(""pdf"", pix.tobytes())
new_doc.insert_pdf(img_pdf)
new_doc.save(output_path)
new_doc.close()
doc.close()
return True
except Exception as e:
print(f""Error compressing {input_path}: {e}"")
return False
def batch_compress_pdfs(input_dir, output_dir, zoom=0.5, progress_callback=None):
if not os.path.exists(output_dir):
os.makedirs(output_dir)
pdf_files = [f for f in os.listdir(input_dir) if f.lower().endswith("".pdf"")]
total_files = len(pdf_files)
for i, filename in enumerate(pdf_files):
input_path = os.path.join(input_dir, filename)
output_path = os.path.join(output_dir, filename)
success = compress_pdf(input_path, output_path, zoom) if is_valid_pdf(input_path) else False
if progress_callback:
progress_callback(i + 1, total_files, filename, success)
def start_compression():
input_dir = input_dir_var.get()
output_dir = output_dir_var.get()
zoom = float(zoom_var.get())
if not input_dir or not output_dir:
messagebox.showerror(""エラー"", ""入力フォルダと出力フォルダを選択してください。"")
return
progress_bar[""value""] = 0
progress_bar[""maximum""] = 100
status_label.config(text=""圧縮を開始します..."")
def update_progress(current, total, filename, success):
percent = int((current / total) * 100)
progress_bar[""value""] = percent
status = ""✓"" if success else ""✗""
status_label.config(text=f""{status} {filename} ({current}/{total})"")
batch_compress_pdfs(input_dir, output_dir, zoom, update_progress)
messagebox.showinfo(""完了"", ""PDFの圧縮が完了しました。"")
def browse_input_folder():
folder = filedialog.askdirectory()
if folder:
input_dir_var.set(folder)
def browse_output_folder():
folder = filedialog.askdirectory()
if folder:
output_dir_var.set(folder)
# GUI setup
root = tk.Tk()
root.title(""PDF一括圧縮ツール"")
input_dir_var = tk.StringVar()
output_dir_var = tk.StringVar()
zoom_var = tk.StringVar(value=""0.5"")
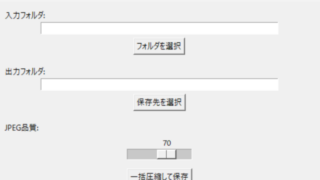
tk.Label(root, text=""入力フォルダ:"").grid(row=0, column=0, sticky=""e"")
tk.Entry(root, textvariable=input_dir_var, width=50).grid(row=0, column=1)
tk.Button(root, text=""参照"", command=browse_input_folder).grid(row=0, column=2)
tk.Label(root, text=""出力フォルダ:"").grid(row=1, column=0, sticky=""e"")
tk.Entry(root, textvariable=output_dir_var, width=50).grid(row=1, column=1)
tk.Button(root, text=""参照"", command=browse_output_folder).grid(row=1, column=2)
tk.Label(root, text=""圧縮率(例: 0.5):"").grid(row=2, column=0, sticky=""e"")
tk.Entry(root, textvariable=zoom_var, width=10).grid(row=2, column=1, sticky=""w"")
tk.Button(root, text=""圧縮開始"", command=start_compression).grid(row=3, column=1, pady=10)
progress_bar = ttk.Progressbar(root, length=400)
progress_bar.grid(row=4, column=0, columnspan=3, pady=5)
status_label = tk.Label(root, text="""")
status_label.grid(row=5, column=0, columnspan=3)
root.mainloop()
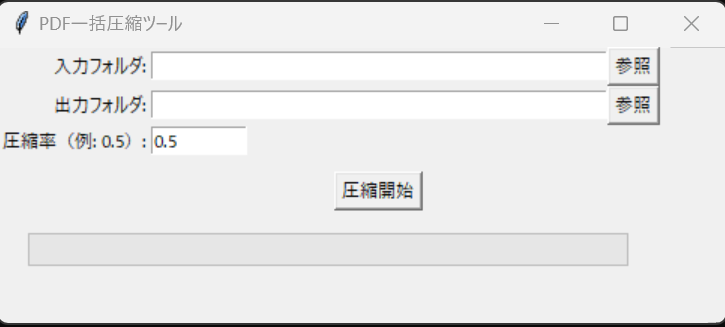
表示されるGUI
- 「圧縮率」は画像化するときのズーム倍率
- 数値を下げると → 画質は落ちるがサイズは小さくなる
- 数値を上げると → 画質は上がらず、むしろサイズが大きくなる
📝 まとめ
- 画像ベースのPDFは圧縮可能だが、図面やベクター形式のPDFは難しい
- 圧縮できないPDFは、再保存や変換で対応可能
- Pythonスクリプトで業務効率化できるが、ファイルの種類に応じた工夫が必要
あわせて読みたい
※PR(アフィリエイト広告)を含みます
要件がふわっとしててもOK。
まずは無料相談で相場確認できます。
「何を頼めばいいか分からない」
「いくらかかるか不安」でも大丈夫。
目的と入出力イメージだけ送れば、見積もりが早く正確になります。
✅ 送るとスムーズ:目的 / 入力データ例 / 期待する出力 / OS / 納期
✅ 追加費用を防ぐ:成果物(コード+実行手順)と検収条件を先に決める